2. LOS SISTEMAS DE BASES DE DATOS Y LOS SGBD.
Lecturas recomendadas: ELMASRI y NAVATHE, 1989; MIGUEL y PIATTINI, 1993; FROST, 1989; KORTH y SILBERSCHATZ, 1993; MOTA, CELMA y CASAMAYOR, 1994; BATINI, CERI y NAVATHE, 1994; JACKSON, 1990; REINGRUBER y GREGORY, 1994, BERTINO y MARTINO, 1995.
Una de las conclusiones obtenidas en el capítulo anterior era que los recursos de información, y los mecanismos necesarios para su interrogación, resultaban ser uno de los objetivos fundamentales en los sistemas de información que debían hacer frente a grandes cantidades de documentos e información en diferentes formatos y soportes. Y uno de los componentes principales de estos sistemas son las bases de datos, o, más concretamente, los sistemas de bases de datos. Resultará evidente, por otra parte, que la gestión del gran volumen de datos demandará una teoría sobre la organización de esos datos para alcanzar la máxima efectividad posible. En este capítulo se va a efectuar una revisión de los principios que inspiran la arquitectura y el diseño de sistemas de bases de datos, poniendo especial interés en el modelo entidad-relación, por cuanto será el utilizado más adelante para el diseño de las bases de datos con sistemas de gestión de bases de datos relacionales, ya que gran parte de los métodos de modelado conceptual pueden utilizarse igualmente en la construcción de bases de datos documentales.
2.1. Las bases de datos.
En el entorno informático, la gestión de bases de datos ha evolucionadodesde ser una aplicación más disponible para los computadores, a ocupar un lugar fundamental en los sistemas de información. En la actualidad, un sistema de información será más valioso cuanto de mayor calidad sea la base de datos que lo soporta, la cual resulta a su vez un componente fundamental del mismo, de tal forma que puede llegarse a afirmar que es imposible la existencia de un sistema de información sin una base de datos, que cumple la función de "memoria", en todas sus acepciones posibles, del sistema.
Las bases de datos almacenan, como su nombre dice, datos. Estos datos son representaciones de sucesos y objetos, a diferente nivel, existentes en el mundo real: en su conjunto, representan algún tipo de entidad existente. En el mundo real se tiene percepción sobre las entidades u objetos y sobre los atributos de esos objetos; en el mundo de los datos, hay registros de eventos y datos de eventos. Además, en ambos escenarios se puede incluso distinguir una tercera faceta: aquella que comprende las definiciones de las entidades externas, o bien las definiciones de los registros y de los datos.
La transferencia entre las entidades del mundo real, y sus características, y los registros contenidos en una base de datos, correspondientes a esas entidades, se alcanza tras un proceso lógico de abstracción, conjunto de tareas que suelen englobarse bajo el título de diseño de bases de datos.
Sin embargo, es necesario definir, en primer lugar, qué es una base de datos, independientemente de su diseño y/o su orientación. Entre las numerosas definiciones que pueden encontrarse en la bibliografía, pueden escogerse, por su exhaustividad, las siguientes:
"Colección de datos correspondientes a las diferentes perspectivas de un sistema de información (de una empresa o institución), existentes en algún soporte de tipo físico (normalmente de acceso directo), agrupados en una organización integrada y centralizada en la que figuran no sólo los datos en sí, sino también las relaciones existentes entre ellos, y de forma que se minimiza la redundancia y se maximiza la independencia de los datos de las aplicaciones que los requieren." (GUILERA, 1993: 377)
"Una base de datos es una colección de datos estructurados según un modelo que refleje las relaciones y restricciones existentes en el mundo real. Los datos, que han de ser compartidos por diferentes usuarios y aplicaciones, deben mantenerse independientes de éstas, y su definición y descripción han de ser únicas estando almacenadas junto a los mismos. Por último, los tratamientos que sufran estos datos tendrán que conservar la integridad y seguridad de éstos." (MOTA, CELMA y CASAMAYOR, 1994: 9)
La segunda definición añade los objetivos que debe cumplir un sistema de gestión de bases de datos, sobre los cuales se tratará más adelante. Por ahora, basta considerar que deben cumplir los objetivos de independencia de los datos (las aplicaciones no deben verse afectadas por cambios en la estructura de los datos), integridad de los datos (los datos deben cumplir ciertas restricciones que aseguren la correcta introducción, modificación y borrado de los mismos) y seguridad (establecer diferentes niveles de acceso a los datos a diferentes tipos de usuarios).
La entidad existente en el mundo real es objeto de un doble tratamiento, desde el momento en que convierte en objeto de la base de datos. El tratamiento de sus datos se va a realizar en un nivel lógico, por una parte, y en un nivel físico, por otra. En el primero de ellos, el lógico, se va a trabajar en los aspectos referidos a la identificación de las características de la entidad, su descripción y organización, mientras que en el segundo todo lo anterior se va a plasmar en la organización, acceso y almacenamiento de los datos en un soporte físico. Esta división entre un nivel lógico y otro físico se va reflejar en todos los métodos y conceptos subsiguientes.
2.2. El modelo de arquitectura de bases de datos.
Hasta fecha relativamente cercana, las bases de datos eran el resultado de una compleja programación y de complicados mecanismos de almacenamiento. Con la popularización de la microinformática, la aparición de aplicaciones específicas también trajo con ella la disponibilidad de herramientas de gestión de datos, que acabaron desembocando en los denominados sistemas de gestión de bases de datos, identificados por sus siglas SGBD (DBMS en inglés, siglas de DataBase Management Systems). De esta manera, la gestión de base de datos pudo liberarse de los grandes ordenadores centrales, pudiendo distribuirse según los intereses de los usuarios, y dotando de autonomía en la gestión de información a muchas entidades. Los SGBD permitieron a todo tipo de usuarios crear y mantener sus bases de datos, dotándolos de una herramienta que era capaz de transformar el nivel lógico que éstos diseñaban en un conjunto de datos, representaciones y relaciones, traduciéndolo al nivel físico correspondiente. Para que fuese posible, y para asegurar a los usuarios cierta seguridad en el intercambio de datos entre diferentes sistemas, y en el diseño de ficheros y bases de datos, fue necesario normalizar los esquemas que guiaban la creación de las bases de datos.
Las bases de datos respetan la arquitectura de tres niveles definida, para cualquier tipo de base de datos, por el grupo ANSI/SPARC. En esta arquitectura la base de datos se divide en los niveles externo, conceptual e interno (KORTH y SILBERSCHATZ, 1994:5; MIGUEL y PIATTINI, 1993: 83-107; MOTA, CELMA y CASAMAYOR, 1994: 11-12):
- Nivel interno: es el nivel más bajo de abstracción, y define cómo se almacenan los datos en el soporte físico, así como los métodos de acceso.
- Nivel conceptual: es el nivel medio de abstracción. Se trata de la representación de los datos realizada por la organización, que recoge las vistas parciales de los requerimientos de los diferentes usuarios y las aplicaciones posibles. Se configura como visión organizativa total, e incluye la definición de datos y las relaciones entre ellos.
- Nivel externo: es el nivel de mayor abstracción. A este nivel corresponden las diferentes vistas parciales que tienen de la base de datos los diferentes usuarios. En cierto modo, es la parte del modelo conceptual a la que tienen acceso.
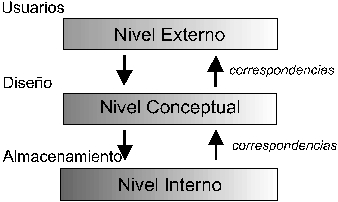
Fig. 2.1. Niveles de la arquitectura de bases de datos.
En ocasiones puede encontrarse el nivel conceptual divido en dos niveles, conceptual y lógico. El primero de ellos corresponde a la visión del sistema global desde un punto de vista organizativo independiente, no informático. El segundo correspondería a la visión de la base de datos expresada en términos del sistema que se va a implantar con medios informáticos.
El modelo de arquitectura propuesto permite establecer el principio de independencia de los datos. Esta independencia puede ser lógica y física. Por independencia lógica se entiende que los cambios en el esquema lógico no deben afectar a los esquemas externos que no utilicen los datos modificados. Por independencia física se entiende que el esquema lógico no se vea afectado por cambios realizados en el esquema interno, correspondientes a modos de acceso, etc.
2.3. Los modelos de datos.
En el proceso de abstracción que conduce a la creación de una base de datos desempeña una función prioritaria el modelo de datos. El modelo de datos, como abstracción del universo de discurso, es el enfoque utilizado para la representación de las entidades y sus características dentro de la base de datos, y puede ser dividido en tres grandes tipos (KORTH y SILBERSCHATZ, 1993: 6-11):
- Modelos lógicos basados en objetos: los dos más extendidos son el modelo entidad-relación y el orientado a objetos. El modelo entidad-relación (E-R) se basa en una percepción del mundo compuesta por objetos, llamados entidades, y relaciones entre ellos. Las entidades se diferencian unas de otras a través de atributos. El orientado a objetos también se basa en objetos, los cuales contienen valores y métodos, entendidos como órdenes que actúan sobre los valores, en niveles de anidamiento. Los objetos se agrupan en clases, relacionándose mediante el envío de mensajes. Algunos autores definen estos modelos como "modelos semánticos".
- Modelos lógicos basados en registros: el más extendido es el relacional, mientras que los otros dos existentes, jerárquico y de red, se encuentran en retroceso. Estos modelos se usan para especificar la estructura lógica global de la base de datos, estructurada en registros de formato fijo de varios tipos. El modelo relacional representa los datos y sus relaciones mediante tablas bidimensionales, que contienen datos tomados de los dominios correspondientes. El modelo de red está formado por colecciones de registros, relacionados mediante punteros o ligas en grafos arbitrarios. el modelo jerárquico es similar al de red, pero los registros se organizan como colecciones de árboles. Algunos autores definen estos modelos como "modelos de datos clásicos".
- Modelos físicos de datos: muy poco usados, son el modelo unificador y el de memoria de elementos. Algunos autores definen estos modelos como "modelos de datos primitivos".
De lo anterior se deduce que el punto clave en la construcción de la base de datos será el modelo de datos. Se denomina modelo:
"...al instrumento que se aplica a una parcela del mundo real (universo del discurso) para obtener una estructura de datos a la que denominamos esquema. Esta distinción entre el modelo (instrumento) y el esquema (resultado de aplicar el instrumento) es importante... Es importante también distinguir entre mundo real y universo del discurso, ya que este último es la visión que del mundo real tiene el diseñador... podemos definir un modelo de datos como un conjunto de conceptos, reglas y convenciones que nos permiten describir los datos del universo del discurso." (MIGUEL y PIATTINI, 1993: 162)
Los objetivos del modelo de datos son dos:
- Formalización: definir formalmente las estructuras permitidas y las restricciones a fin de representar los datos de un SI.
- Diseño: el modelo resultante es un elemento básico para el desarrollo de la metodología de diseño de la base de datos.
Los diferentes modelos de datos comparten, aunque con diferentes nombres y notaciones, unos elementos comunes, componentes básicos de la representación de la realidad que realizan. Estos componentes se identifican gracias a la clasificación, y pueden identificarse conceptos estáticos y conceptos dinámicos. Los conceptos estáticos corresponden a:
- Objeto: cualquier entidad con existencia independiente sobre el que almacenan datos. Puede ser simples o compuestos.
- Relación: asociación entre objetos.Restricción estática: propiedad estática del mundo real que no puede expresarse con los anteriores, ya que sólo se da en la base de datos; suele corresponder a valores u ocurrencias, y puede ser sobre atributos, entidades y relaciones.
- Objeto compuesto: definidos como nuevos objetos dentro de la base de datos, tomando como punto de partida otros existentes, mediante mecanismos de agregación y asociación.
- Generalización: se trata de relaciones de subclase entre objetos, es decir, parte de las características de diferentes entidades pueden resultar comunes entre ellas.
Por su parte, los conceptos dinámicos responden a:
- Operación: acción básica sobre objetos o relaciones (crear, modificar, eliminar...).
- Transacción: conjunto de operaciones que deben ejecutarse en su conjunto obligatoriamente.
- Restricción dinámica: propiedades del mundo real que restringen la evolución en el tiempo de la base de datos.
2.4. Los sistemas de gestión de bases de datos.
Para plasmar los tres niveles en el enfoque o modelo de datos seleccionado, es necesaria una aplicación que actúe de interfaz entre el usuario, los modelos y el sistema físico. Esta es la función que desempeñan los SGBD, ya reseñados, y que pueden definirse como un paquete generalizado de software, que se ejecuta en un sistema computacional anfitrión, centralizando los accesos a los datos y actuando de interfaz entre los datos físicos y el usuario. Las principales funciones que debe cumplir un SGBD se relacionan con la creación y mantenimiento de la base de datos, el control de accesos, la manipulación de datos de acuerdo con las necesidades del usuario, el cumplimiento de las normas de tratamiento de datos, evitar redundancias e inconsistencias y mantener la integridad. Se han señalado como componentes de un sistema ideal de gestión de bases de datos los siguientes (FROST, 1989: 90):
- Un lenguaje de definición de esquema conceptual.
- Un sistema de diccionario de datos.
- Un lenguaje de especificación de paquetes de entrada/salida.
- Un lenguaje de definición de esquemas de base de datos.
- Una estructura simétrica de almacenamiento de datos.
- Un módulo de transformación lógica a física.
- Un subsistema de privacidad de propósito general.
- Un subsistema de integridad de propósito general.
- Un subsistema de reserva y recuperación de propósito general.
- Un generador de programas de aplicación.
- Un generador de programas de informes.
- Un lenguaje de consulta de propósito general.
El SGBD incorpora como herramienta fundamental dos lenguajes, para la definición y la manipulación de los datos. El lenguaje de definición de datos (DDL, Data Definition Language) provee de los medios necesarios para definir los datos con precisión, especificando las distintas estructuras. Acorde con el modelo de arquitectura de tres niveles, habrá un lenguaje de definición de la estructura lógica global, otro para la definición de la estructura interna, y un tercero para la definición de las estructuras externas.
El lenguaje de manipulación de datos (DML, Data Manipulation/ Management Language), que es el encargado de facilitar a los usuarios el acceso y manipulación de los datos. Pueden diferenciarse en procedimentales (aquellos que requieren qué datos se necesitan y cómo obtenerlos) y no procedimentales (que datos se necesitan, sin especificar como obtenerlos), y se encargan de la recuperación de los datos almacenados, de la inserción y supresión de datos en la base de datos, y de la modificación de los existentes.
Establecidos los conceptos de bases de datos, su arquitectura y las características de las aplicaciones que soportan su gestión, es conveniente revisar los pasos o fases que sigue la ejecución de una tarea cualquiera por parte del sistema de gestión de bases de datos (MOTA, CELMA y CASAMAYOR, 1994: 13-14):
- Petición de la aplicación del usuario.
- Examen de la petición en el marco del esquema externo del usuario.
- Transformación del esquema externo al lógico.
- Transformación del esquema lógico al interno.
- Interacción con el almacenamiento físico.
- Envío de los datos a los buffers del SGBD.
- Transformaciones de los datos entre el esquema lógico y el externo.
- Transferencia de los datos necesarios al área de trabajo del usuario.
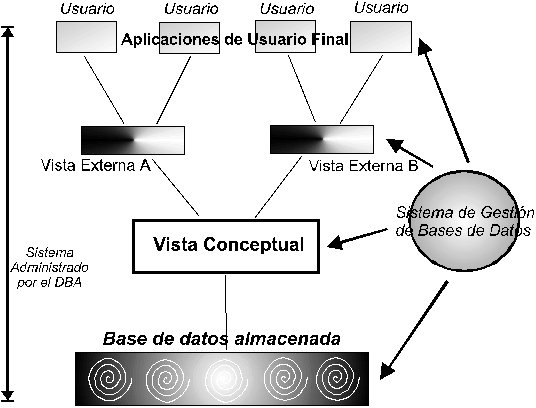
Fig. 2.2. Arquitectura de un Sistema de Bases de Datos.
2.5. Los usuarios.
En consonancia con las posibles, y diferentes, vistas externas, se pueden identificar varios tipos de usuarios. En primer lugar, los usuarios finales, que hacen un uso limitado de las capacidades del sistema, normalmente referentes a introducción, manipulación y consulta de los datos. Los usuarios finales pueden ser sofisticados o especializados e ingenuos, dependiendo de su nivel de interacción con el sistema. En segundo lugar hay que citar a los programadores de base de datos, encargados de escribir aplicaciones limitadas, mediante el lenguaje de programación facilitado por el SGBD, normalmente algún lenguaje de cuarta generación, que faciliten la ejecución de tareas por parte de los usuarios finales. Por último, el administrador de base de datos (DBA, Data Base Administrator) cumple las importantes funciones de crear y almacenar las estructuras de la base de datos, definir las estrategias de respaldo y recuperación, vincularse con los usuarios y responder a sus cambios de requerimientos, y definir los controles de autorización y los procedimientos de validación.
2.6. La creación de bases de datos.
Con los antecedentes señalados, se inicia la creación de las bases de datos. En primer lugar, y acorde con los diferentes niveles de arquitectura de bases de datos reseñados, tiene lugar la construcción del modelo y del esquema conceptual de la base de datos (REINGRUBER y GREGORY, 1994).
2.6.1. El esquema conceptual.
El esquema conceptual puede definirse como una descripción abstracta y general de la parte o sector del universo real que el contenido de la base de datos va a representar, llamada en ocasiones "universo del discurso". En este nivel de análisis se está tratando con una descripción de la realidad, no con datos, y suele contener listas de tipos de entidades, de las relaciones existentes entre esas entidades y de las restricciones de integridad que se aplican sobre ellas. El esquema conceptual de la base de datos puede utilizarse para integrar los intereses de los diferentes usuarios, como herramienta de representación y de formación, así como para prever futuras modificaciones del sistema. En el aspecto de la representación, lo más interesante es utilizar algún tipo de especificación formal en sentido matemático, lo que facilita la consistencia y los análisis lógicos de los esquemas propuestos. Del esquema conceptual formalizado pueden derivarse diferentes subesquemas conceptuales, que representan aquellas partes del esquema conceptual de interés para un usuario o grupo de usuarios finales.
2.6.2. El esquema de la base de datos.
Una vez construido el esquema conceptual, el diseño de bases de datos obliga a realizar varias tareas previas a la construcción del esquema lógico global del sistema, también llamado esquema de bases de datos. Por el momento, basta saber que el esquema de la base de datos representa la descripción de los datos de la base de datos, mientras que el esquema conceptual representaba a la realidad. La primera de las tareas necesarias es la identificación de los datos requeridos, para obtener como resultado las partes del área de aplicación que deben representarse mediante datos, y en que forma deben presentarse éstos a los usuarios. El siguiente paso es el análisis de datos, consistente en la definición y clasificación de esos datos, su descripción, que suele presentarse en forma de diccionario de datos, como una "metabase de datos". Por último, debe hacerse la especificación de los paquetes de entrada y de salida, correspondientes con los datos que deben introducir y obtener como respuesta los usuarios, según sus necesidades. Las tres tareas habrán permitido obtener tres documentos sobre descripción del área de aplicación, definición y clasificación de los datos y especificación de las características de los diversos paquetes, respectivamente. Tomando como punto de partida estos tres elementos, se construye la especificación de esquema de la base de datos, que responderá al contenido total de la base de datos y las características de las vías de acceso requeridas a través de estos datos. Frente al análisis de datos, que es la definición y clasificación de los datos, el esquema se encarga de la utilización de esos datos.
2.6.3. El diccionario de recursos de información.
La gestión efectiva de los datos involucrados en la base de datos implica necesariamente disponer de alguna herramienta que controle las características y funciones de aquéllos (MIGUEL y PIATTINI,1995). Esta función es cubierta mediante el diccionario de recursos de información (DRI),que asegura la integración de toda la información contenida en el sistema. Se habla entonces de metadatos, como datos que definen y describen los datos existentes en el sistema. En un primer momento, este tipo de cuestiones eran resueltas a través de los diccionarios de datos, que reunían información sobre los datos almacenados, sus descripciones, significados, restricciones, usos, etc., y los directorios de datos, subsistemas del sistema de gestión, encargados de describir dónde y cómo se almacenaban los datos, Actualmente se aplica el concepto de diccionario de recursos de información, que engloban todo lo señalado anteriormente, dando lugar a lo que ha pasado a llamarse "metabases".
2.6.4. El enfoque de tratamiento de los datos.
La construcción de los modelos conceptual y lógico de las bases de datos requiere la adopción de un determinado enfoque para la descripción y el tratamiento de los datos. Sin embargo, es necesario insistir en que la modelización de datos se orienta al conocimiento en profundidad de los datos que va a manejar la organización, para lograr una implantación óptima. La unión del modelo de datos con el sistema de gestión de base de datos dará como resultado la base de datos real. El modelo de datos será una representación gráfica orientada a la obtención de las estructuras de datos de forma metódica y sencilla, agrupando esos datos en entidades identificables e individualizables, y será reflejo del sistema de información en estudio.
2.7. Creación de una base de datos: enfoque E/R y transformación relacional.
2.7.1. El enfoque entidad-relación de Chen.
Por sus características, se ha seleccionado el enfoque entidad-relación propuesto por Chen (CHEN, 1976; MOTA, CELMA Y CASAMAYOR, 1994; KORTH y SILBERSCHATZ, 1993: 25-226; BATINI, CERI y NAVATHE, 1994). Este modelo toma como punto de partida considerar la existencia de entidades, que representan objetos, personas, etc, sobre las que se quiere almacenar información relevante. Las entidades con las mismas características forman un tipo de entidad. A las características necesarias para describir completamente a cada tipo de entidad se les denominará atributo. Posteriormente, las entidades y sus atributos se representan físicamente a través de tablas (transformación en un modelo relacional) en las que los datos se almacenan en dos dimensiones. Las filas de la tabla contienen los atributos de cada una de las entidades, y las columnas el conjunto de atributos del mismo tipo de cada entidad. El grado de la tabla corresponderá al número de columnas de la tabla. En este momento estaremos trasladando el modelo semántico entidad/relación al modelo clásico relacional, se decir, la transformación entre el modelo conceptual y el lógico. El principio fundamental en este modelado, que no puede obviarse de ninguna forma, es que hechos distintos deben almacenarse en objetos distintos.
Uno de los puntos fuertes de este modelo es que prevé que las entidades puedan mantener relaciones entre ellas. En primer lugar, es necesario definir la clave de la entidad. La claves serán el atributo, o conjunto de atributos, perteneciente al mismo tipo de entidad que hacen único el acceso a esa entidad u ocurrencia de la tabla, determinando de esta forma a una única entidad. La presencia de varios atributos que pueden funcionar como clave da lugar a la existencia de claves candidatas, y por otra parte se puede hablar de claves simples (formadas por un único atributo) y claves múltiples, compuestas o concatenadas (formadas por un conjunto de atributos. No hay que obviar tampoco el concepto de clave ajena, aquel atributo de una tabla que puede funcionar como clave en otra. La ocurrencia de entidad será, en este contexto, cada uno de los posibles valores reales que puede tomar la clave de una entidad.
Las relaciones entre tablas, basadas en la conexión de éstas a través de las claves, pueden ofrecer diferentes cardinalidades, entendiendo como tal el número de ocurrencias de una entidad que se relacionan con ocurrencias de la otra entidad. Pueden identificarse tres tipos: (1,1), donde una ocurrencia se relaciona con otra; (1,m), donde una ocurrencia puede relacionarse con varias; y (m,n), donde varias ocurrencias de una entidad pueden relacionarse con varias ocurrencias de la otra entidad.
- El modelo de Chen es n-ario, lo cual quiere decir que las relaciones pueden establecerse entre una, dos o más entidades. Las entidades pueden ser de dos tipos: Entidad regular: aquella sobre la que se puede definir la clave primario dentro de sus propios atributos.
- Entidad débil: aquellas que no puede utilizar sus propios atributos como clave, al estar asociada a otra entidad.
La definición del modelo conceptual con la técnica propuesta por Chen propone una secuencia de fases para la obtención del modelo:
- Identificar las entidades dentro del sistema: para ello, debe conocerse el funcionamiento del sistema en estudio, a través de estudios de usuarios, de necesidades de información, de tipos de información, etc. Como guía puede utilizarse para la definición de las entidades objetos reales, personas, actividades del sistema, objetos abstractos, etc.
- Determinar las claves o identificadores de entidades: señalar aquellos atributos que identifiquen inequívocamente cada ocurrencia de la entidad, y que no puedan ofrecer valores nulos.
- Establecer las relaciones entre la entidades, describiendo el grado de las mismas: estudiar las asociaciones entre las entidades, para definir su importancia dentro del contexto del sistema, y obtener su cardinalidad.
- Dibujar el modelo de datos: representar gráficamente el modelo obtenido.
- Identificar y describir los atributos de cada entidad: señalar aquellas propiedades de la entidad de interés para el sistema.
- Verificaciones: eliminación de las relaciones redundantes y que puedan ser obtenidas a través de combinar otras asociaciones.
El modelo obtenido se representa mediante una notación gráfica especializada, a través de diagramas, cuyas normas generales y variantes especializadas pueden encontrase en la bibliografía pertinente.
2.7.2. La normalización.
El modelo conceptual de datos obtenido mediante la técnica de entidad-relación será refinado y convertido en un modelo lógico relacional, utilizando la normalización, lo que ofrecerá como resultado el conjunto de tablas a implementar en la base de datos (JACKSON, 1990; MIGUEL Y PIATTINI, 1993: 425-674). Su finalidad es reducir las inconsistencias y redundancias de los datos, facilitar el mantenimiento y evitar las anomalías en las manipulaciones de datos. El objetivo será obtener un modelo lógico normalizado que represente las entidades normalizadas y las interrelaciones existentes entre ellas. Para ello, se toma como punto teórico de partida el concepto de dependencia funcional, que dice: "Un atributo B depende funcionalmente de otro atributo A, de la misma entidad si a cada valor de A le corresponde sólo un valor de B." Lo anterior se completa mediante la dependencia funcional completa y la dependencia transitiva.
El procedimiento de normalización consiste en someter a las tablas que representan entidades a un análisis formal para ver si cumplen, o no, las restricciones necesarias que aseguren evitar los problemas citados con anterioridad. A mayor nivel de normalización, mayor calidad en la organización de los datos y menor peligro para la integridad de los datos. Este procedimiento consiste en ir alcanzando formas normales
Todo el proceso se basa en que una primera relación universal plantearía enormes problemas de redundancia, consistencia e integridad de los datos, por lo que es necesario mejorar las relaciones. Estas mejoras deben dar como resultado tablas equivalentes y mejores que sus respectivas originales, y poseer siempre tres propiedades: conservación de la información (de atributos y de tuplas), conservación de dependencias y mínima redundancia de los datos. Las mejoras introducidas obligan a plantear hasta que Forma Normal es necesario llegar, es decir, a que nivel de depuración. Normalmente, es recomendable alcanzar la máxima Forma Normal, aunque luego es muy probable que restricciones existentes, de algún tipo, obliguen a retroceder a un nivel inferior de normalización, o incluso a cierto nivel de "desnormalización".
2.8. Propuesta de un método estándar de diseño.
Con los métodos que se han expuesto, el diseño de una base de datos relacional puede seguir dos caminos. Por una parte, puede crearse tomando como punto de partida la observación del universo en estudio, dando lugar a un conjunto de esquemas de relaciones, que contengan los atributos y sus restricciones. Por otra parte, puede dividirse el diseño en dos fases, la primera de las cuales sería definir el modelo conceptual y su esquema, y la segunda transformar el esquema conceptual en un esquema relacional mediante una transformación realizada de acuerdo a unas reglas dadas.
Sin perjuicio del rigor en el diseño relacional, el diseño de una base de datos no puede limitare a la aplicación exclusiva de la teoría de la normalización. Del mismo modo que se ha visto la existencia de variadas metodologías en el ámbito de los sistemas de información, se encuentra el mismo panorama en el diseño de bases de datos, aunque aquí tampoco aparece una metodología consagrada. De esta forma, Elmasri y Navathe comparan el ciclo de diseño de los sistemas de información y de las bases de datos, y definen el problema de diseñar una base de datos como:
"Desing the logical and physical structure of one or more databases to accommodate the information needs of the users in an organization for a defined set of applications"(ELMASRI y NAVATHE, 1989: 457)
y señalan la existencia de seis fases en el proceso de diseño de una base de datos:
Fase 1: Recopilación y análisis de requerimientos.
En esta fase se trata de conocer las expectativas del usuario sobre la base de datos. Para ello, se identifican los grupos de usuarios reales y posibles y las áreas de aplicación, se revisa la documentación existente, se analiza el entorno operativo y los requerimientos de procesado, y se realizan entrevistas y cuestionarios con los usuarios. Para todo ello existen técnicas formalizadas de especificación de requerimientos.
Fase 2: Diseño conceptual de la base de datos.
Esta fase se subdivide en otras dos. La Fase 2a corresponde al Diseño del esquema conceptual, esquema de especificación del modelo de datos a alto nivel, independiente de cualquier SGBD, que no puede utilizarse para implementar directamente la estructura de la base de datos. Para obtenerlo puede adoptarse un enfoque de esquema centralizado (en el cual se unen previamente los diferentes requerimientos a la realización del esquema), o un enfoque de integración de vistas (en el cual se unen los esquemas de cada requerimiento en uno global realizado a posteriori). La Fase 2b corresponde al diseño de transacciones, es decir, a aquellas aplicaciones que van a manipular datos contenidos en la base de datos. Se suelen identificar mediante el estudio de las entradas y salidas de datos y su comportamiento funcional. De esta forma se identifican transacciones de recuperación, de actualización y mixtas.
Fase 3: Elección de un SGBD.
Se consideran diferentes factores técnicos, económicos y de beneficio, de servicio técnico y formación de usuarios, organizativos de rendimiento, etc. Sin embargo, resulta difícil la medida y cuantificación ponderada de los diferentes factores.
Fase 4: Transformación del modelo de datos (o fase de diseño lógico).
En esta fase se crea un esquema conceptual y los esquemas externos necesarios en el modelo de datos del SGBD seleccionado, mediante la transformación de los esquemas de modelo de datos a alto nivel obtenidos en la Fase 2a, al modelo de datos ofrecido por el SGBD.
Fase 5: Diseño de la base de datos física.
Consiste en definir las estructuras de almacenamiento y de acceso para alcanzar una rendimiento óptimo de las aplicaciones de la base de datos. Los criterios adoptados suelen ser el tiempo de respuesta, la utilización de espacio y el volumen de transacciones por minuto.
Fase 6: Implementación del sistema de base de datos.
En esta fase final se hace realidad la base de datos, mediante la creación y la compilación del esquema de bases de datos y de los ficheros de bases de datos, así como de las transacciones, a través de las aplicaciones.
La metodología expuesta, que puede servir como marco de referencia general, puede modificarse según las características del contexto en el que se diseña e implanta el sistema de bases de datos.
En el dinámico entorno de la información almacenada en las bases de datos, las recientes tendencias, derivadas en muchas ocasiones de las propias necesidades, han obligado a completar e incorporar nuevos conceptos y enfoques en el tratamiento de los datos. Por ejemplo, la existencia de relaciones complejas en el mundo real han obligado a la incorporación del modelado semántico, lo que ha dado como resultado la evolución del modelo entidad-relación extendido, con sus conceptos de superclases y subclases, y los procesos de generalización y especialización, así como la importante noción de herencia. También es necesaria la referencia ineludible al paradigma de la orientación a objetos (BERTINO y MARTINO, 1995), enfoque de tratamiento de la información que cobra cada vez mayor auge en aplicaciones comerciales, y que se configura como la opción de mayor futuro en el desarrollo de aplicaciones. La identificación de los datos y sus procesos como objetos individuales, el encapsulamiento y las propiedades de herencia son las características principales del enfoque a objetos. Por último, no puede olvidarse la creciente tendencia entre el enfoque relacional y el modelo de objetos, así como la integración de información referenciada espacialmente en modelos relacionales.
Es innegable que la gestión y la explotación subsiguiente de los registros que contienen datos, y, como consecuencia, información, depende de las herramientas existentes en el campo de la gestión de la información, por una parte, y del cuerpo teórico de la ciencia de la información, por otra. La explotación satisfactoria de esta información, de la misma forma, demanda experiencia en dos áreas de conocimiento: en las técnicas de recuperación de información y en el estudio de las necesidades de los usuarios.